在 Day 2 生成式 AI 的歷史演變有提到,現在的生成式 AI 模型都是基於 Transformer 衍伸而來的,今天就來一探究竟。
Transformer 模型的核心是自注意力機制 (Self-Attention Mechanism),允許模型在處理輸入序列中每個單位的位置時,同時考慮整個序列中每個單位的所有位置,更有效地取得序列中的長距離相依關係。
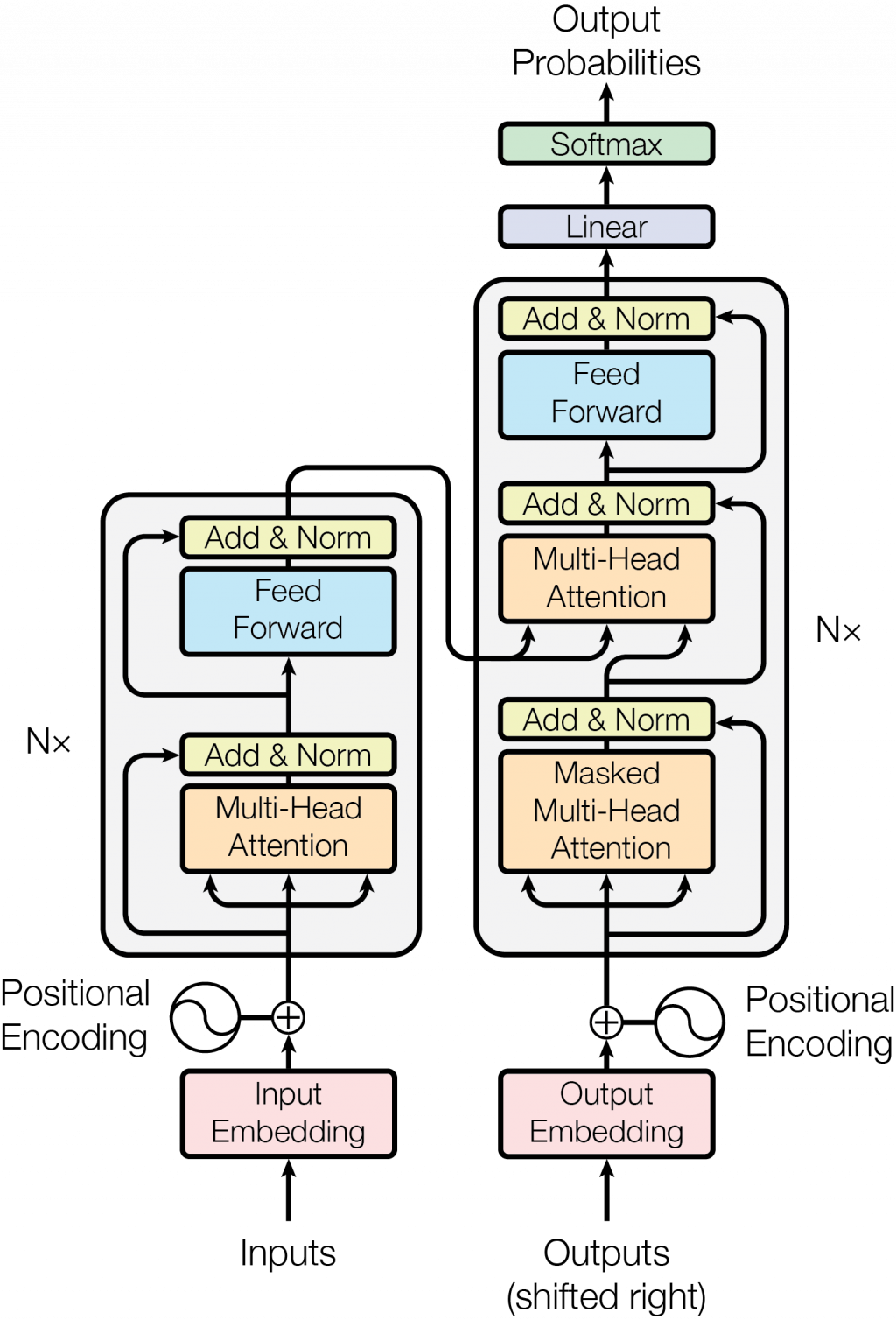
圖片來源:Attention Is All You Need
Transformer 的架構包括編碼器 (Encoder) 和解碼器 (Decoder) 兩部分,這兩部分都由多層相同的模組堆疊而成。每一層模組包括兩個子層級:多頭自注意力機制 (Multi-Head Self-Attention Mechanism) 和前饋神經網路 (Feed-Forward Neural Network)。這些子層級都使用了殘差連結 (Residual Connection) 和層級標準化 (Layer Normalization) 來穩定訓練過程。
多頭自注意力機制
多個 Attention Heads
在多頭自注意力機制中,輸入的 Query、Key 和 Value 向量會被映射到多個不同的子空間,每個子空間對應一個 Attention Head。
每個 Attention Head 會在其對應的子空間內獨立執行自注意力機制,計算出一組注意力分數和加權求和結果。這意味著,每個 Attention Head 可以專注於取得序列中的不同特徵。
線性投影
對於每個 Attention Head,模型會應用不同的線性投影(即不同的權重矩陣)來生成 Query、Key 和 Value 向量。這些投影使得每個 Attention Head 能夠在不同的表示空間中進行操作。
平行計算
所有 Attention Heads 的計算都是平行進行的。這種平行計算使得模型可以在相同的時間步內考慮輸入序列的多個方面,而不必逐步處理,從而提高了計算效率。
Attention Heads 的輸出合併
每個 Attention Head 都會生成一個輸出向量,這些向量代表了該 Attention Head 對輸入序列的不同理解。這些輸出向量會被串連 (concatenate) 在一起,形成一個向量。
然後這個向量會再通過一個線性層 (Linear Layer),將其重新映射回原來的維度。這一步驟的結果就是最終輸出。
前饋神經網路
前饋神經網路結構主要有三層,輸入層 (Input Layer)、隱藏層 (Hidden Layer) 和輸出層 (Output Layer)
輸入層
輸入層接收外部資料,將其轉換為神經網路的輸入特徵。輸入層的每個神經元代表一個特徵或一個資料點,通常不進行任何計算,只是將資料傳遞到下一層。
隱藏層
隱藏層位於輸入層和輸出層之間,是前饋神經網路中的核心計算單元。每個隱藏層的神經元都接收來自前一層的輸入,透過權重進行加權求和,然後透過一個非線性激勵函式 (Non-Linear Activation Function) 進行變換。隱藏層的數量和每層的神經元數決定了神經網路的深度 (Depth) 和容量 (Capacity)。
輸出層
輸出層是前饋神經網路的最終層,它將最後一個隱藏層的輸出進行處理,生成模型的最終預測結果。輸出層的神經元數量通常與預測任務的類別數或輸出維度相對應。


 iThome鐵人賽
iThome鐵人賽